
Graduate School
Maybe from time to time you’ve wondered: Who are these scientists running Snapshot Serengeti? How did they get where they are? (And why am I sitting here instead of traipsing across the Serengeti myself?)
Ali and I are both graduate students at the University of Minnesota. What that means is that a while ago (seven years for me!) we filled out an application and wrote some essays for admission to the University of Minnesota’s graduate school — just like you would do for college admissions. The difference is that for graduate school, you also need to identify an advisor — a faculty member who will become both your mentor and your judge — and an area of research that you want to pursue. And while the admissions materials matter, it’s very important that your future advisor want to take you on as a student and that your area of research interest meshes well with hers or his.
In the U.S., you can apply for a Masters program or a Ph.D. program. In some places you can get a Masters on the way to a Ph.D., but that’s not the case at Minnesota. So I applied for the Ph.D., got admitted and started as a Ph.D. student in the fall of 2007. I’m pretty much only going to talk about Ph.D.s from here on out. And I should point out that graduate school systems vary from country to country. I’m just going to talk about how it works in the U.S. because I’m not terribly familiar with what happens in other countries.
For the first 2-3 years in our program, students spend much of their time taking classes. These are mostly higher level classes that assume you already took college-level classes in basic biology, math, etc. I came in with an college degree in computer science, and so a bunch of the classes I took were actually more fundamental ecology and evolution classes so I could get caught up. But many classes are reserved for just graduate students or for grad students plus motivated seniors.
At the same time as taking these classes, students are expected to come up with a research plan to pursue. The first couple years are filled with a lot of anxiety about what exactly to do, and there are plenty of missteps. My first attempt at a research project involved tracking the movement of wildebeest in the Serengeti using satellites and airplane surveys. (Yes, you can see individual wildebeest in Google Earth if you hunt around!) But it turned out not to be a logically or financially feasible project, so I discarded it — after a lot of time and energy investment.
Around the end of the second year and beginning of the third year, grad students in the U.S. take what are called “preliminary” or “comprehensive” exams. These vary from school to school and from department to department. But they usually consist of both a written and oral component. In some places the goal of these exams to to assess whether you know enough about the broad discipline to be allowed to proceed. In other places, the goal is to judge whether or not you’ve put together a reasonable research plan. The program Ali and I are in leans more toward the latter. It requires a written proposal about what you plan to do for research. This proposal is reviewed by several faculty who decide whether it passes or not.
If you pass your written component, you then give a public talk on your proposed research followed by a grueling two to three hour interview with your committee. In our program, students choose their committee members, following a few sets of rules about who can be on it. My committee had five people, including my two advisors. They took turns asking me questions about my proposed research, how I would collect data, analyze it, how I would deal with adversity. The committee then met without me to decide whether I passed or not. (spoiler: I passed)
So, assuming a student passes the preliminary exams, she or he is then considered a “Ph.D. Candidate,” which basically means that all requirements except the actual dissertation itself have been fulfilled. If you’ve ever heard the term “A.B.D.” or “All But Dissertation,” that is what this means. The student got through the first hurdles, but never got a dissertation done (or accepted).
Now it’s time for the research. With luck, persistence, motivation, and lack of confounding factors, a student can do the research and write the dissertation in about three years. Doing research at first is slow because, like learning anything new, you make mistakes. I spent a lot of time gathering data that I’m not going to end up using. Now that I’ve been doing research for a few years, I can better estimate which data is worth collecting and which is not. And so I’m more efficient. While doing research, the student is also reading other people’s related research, and often picking up a side-project or two.
Eventually, the student, together with the advisor(s) and committee members, decides that she or he has done enough research to prove that she or he is a capable professional scientist. All the research gets written up into a massive tome called the dissertation. These days, it’s not uncommon for graduate students in the sciences to write up their dissertation chapters as formal papers that then get published in scientific journals. Sometimes one or more chapters is already published by the time the dissertation is submitted.
When the writing of the dissertation is finished, it gets sent to the committee to read. The student then gives a formal, public talk on the results of the dissertation research, followed by another two to three hour interview with the committee. This time it’s called the “Dissertation Defense,” and the committee asks questions about the research results (and possibly asks the student to fight a snake). The committee then meets without the student and comes up with a decision of whether the student passes or not. There is also often a conditional part of this decision that requires some portion of the dissertation to be revised or added to. So, a decision of “pass, conditional on the following revisions:” is pretty common.
I should mention that while being a grad student has been mostly quite fun, you may not want to drop your day job and run off to academia just yet. There’s the issue of funding. On the plus side, you can acquire funding in the sciences so that you don’t have to take on debt to do your degree (which is not so true in the humanities). Ali and I have both applied for and received fellowships that have allowed us to do most of our graduate program without having to work. But many — maybe most — grad students in the sciences work essentially part-time jobs (20 hours/week) as teaching assistants for faculty. This can really slow down research progress, as well as making some types of research impossible (for example, those that require lengthy trips to the Serengeti). Whether working or on fellowship, students typically gross no more than $30,000 annually, and often less than $25,000, which can be quite reasonable (single person living in a low-cost-of-living area) or prohibitive (person supporting a family living in a high-cost-of-living area). Benefits are pretty much non-existent, with the exception of health coverage, which can range from great (thanks, Minnesota!) to really bad to non-existent.
I mention all this this because I am about to defend my dissertation! In a little less than two weeks I will give a talk, sit down with my committee, and try to convince them I’m a decent scientist. Wish me luck.
The scourge of Daylight Savings Time
As Ali mentioned, we’re working on figuring out timing issues for all the images in Snapshot Serengeti. Each image has a timestamp embedded in it. And that time is Tanzanian time. You might have noticed that sometimes the time associated with an image doesn’t seem to match the time in the photo — especially a night shot with a day time or a day shot with a night time. We initially shrugged that off, saying that some of the times get messed up when the camera gets attacked by an animal.
But it turns out to be more complicated than that. All the times you see on Snapshot Serengeti — either when you click the rightmost icon below the image on the classify screen, or when you look at a capture in Talk — are on West Greenland (or Brazil) time. Why is that? Well, databases like to try to make things “easy” by converting timezones for you. So when the images got loaded up onto the Zooniverse servers, the Snapshot Serengeti database converted all the times from what it thought was Coordinated Universal Time (UTC) to U.S. Central Time, where both Minneapolis and Chicago are. That would mean subtracting six hours. But since the times are really Tanzanian ones, subtracting six hours sticks us in the middle of the Atlantic Ocean (or in Greenland if we go north or Brazil if we go south).
That wouldn’t be so bad, except for Daylight Savings Time. Tanzania, like everywhere close to the equator, doesn’t bother with it. It doesn’t make sense to mess with your times when sunrise and sunset are pretty much as the same time all year round. However, the ever-helpful database located in the U.S. converted the times as if they experience Daylight Savings Time. So on dates during “standard time,” the Snapshot Serengeti times are off by six hours; subtract six hours to find out the actual time the image was taken. But on dates during daylight savings, the times are off by just five hours.

11:35am Tanzanian time. Shown as 4:35pm on Snapshot Serengeti.
And to make things more of a headache for me, those images that got taken during the hour that “disappears” in the spring due to Daylight Savings Time, get tallied as being taken the hour before. This might explain why we get some captures that don’t seem to go together: the images were actually taken an hour apart!
So now I’m focusing on straightening all the timestamps out. And when I do, I’ll ask the Zooniverse developers if we can correct all the times in Snapshot Serengeti so that they’re shown in Tanzanian time. Hopefully we’ll have that all set before Season 7.
By the way, I was able to figure this all out pretty quickly thanks to the awesome blackboard collection that volunteer sisige put together. You can see the actual Tanzanian time on many of the blackboards and confirm that the online time shown below the picture is five or six hours later, depending on the time of year. Many thanks to those of you who tag and comment and put together collections in Talk; what you do is valuable — sometimes in unexpected ways!
Winter vacation
In the winter months (northern hemisphere winter, that is), we catch white storks on camera. They’re taking their winter vacation in the Serengeti — and across eastern and southern Africa.

White storks are carnivorous, eating insects, worms, reptiles, and small mammals. A flock of them like this makes me wonder about the diversity of small critters that they eat that we don’t catch on camera. Because they eat small animals, they can sometimes be seen near fires, ready to gobble up those creatures trying to escape flames and smoke.

The white stork has a favorable reputation with people in both Africa and in Europe, because it feeds on crop pests. In the spring, storks leave their wintering grounds and head north to Europe to breed. They build large nests out of sticks and are happy to do so on buildings and other structures with wide, unencumbered supports. And because they are considered useful — and sometime good luck — people allow them to build their nests on buildings. These nests are then frequently re-used year after year.
Several years ago I went to Poland to find my grandmother’s childhood home. This was made a bit challenging because when my grandmother was a child, the area was part of the Austro-Hungarian Empire and the names of everything — towns, streets — were in German. These days, of course, all the names are in Polish. After finding a list of place name translations, I set out to see if I could locate some buildings my grandmother described in her memoirs in a small town in the countryside outside of what is now Wrocław and was then Breslau. One of these was “Grandfather’s [my great-great-grandfather’s] water mill with its stork nest on the roof.” Sure enough, I found a large old building in the middle of town right by the stream. It no longer sported a water wheel, but there on the roof: a stork’s nest, complete with stork.

Pangolin!
A few weeks ago, Snapshot Serengeti volunteers spotted a Pangolin in Season 6. This is the best pangolin shot we’ve ever seen in this project.

Pangolins are rare and nocturnal, so you don’t see them often out in the field. The pangolin species we have in the Serengeti is called the ground pangolin (Manis temmincki), and it ranges from East Africa though much of Southern Africa.
I once went to Kruger National Park in South Africa for a conference and went on a guided tour in my free time; the tour leader asked what we wanted to see, and I shouted out “pangolin!” The tour leader gave me a withering look and we then went out to see the elephants and giraffes and buffalo that the other tourists were eager to see. I really did want to see a pangolin, though. I’ve never seen one in real life.
Pangolins have scales all along their back and curl up into balls like pillbugs when they feel threatened. They hang out in burrows that they either dig themselves or appropriate from other animals. And they have super long tongues that they use to get to ants and termites, their primary food. Pangolins have one baby at a time, and young pangolins travel by clinging to the base of their mother’s tail.
Pangolins don’t have any close living relatives. In fact, they have an order all to themselves (Pholidota). Because of how they look, scientists used to think they were most closely related to anteaters and armadillos. But now with genetic tools they’ve discovered that pangolins are more closely related to the order Carnivora, which includes all cats and dogs. It’s a bit strange to think that pangolins, which are sometimes called “scaly anteaters” have more in common genetically with lions than with actual anteaters, but that’s what the science tells us.
Many thanks to all of you who marked the new pangolin image in the Talk forum. That lets us make sure it gets classified correctly. ‘Pangolin’ was just one of those rare animals that didn’t make it onto the list of animals you can choose from, so our algorithm will classify it as something else, which we will fix by hand.
Summary of the Experts
Last week, william garner asked me in the comments to my post ‘Better with experience’ how well the experts did on the about 4,000 images that I’ve been using as the expert-identified data set. How do we know that those expert-identifications are correct?
Here’s how I put together that expert data set. I asked a set of experts to classify images on snapshotserengeti.org — just like you do — but I asked them to keep track of how many they had done and any that they found particularly difficult. When I had reports back that we had 4,000 done, I told them that they could stop. Since the experts were reporting back at different times, we actually ended up doing more than 4,000. In fact, we’d done 4,149 sets of images (captures), and we had 4,428 total classifications of those 4,149 captures. This is because some experts got the same capture.
Once I had those expert classifications, I compared them with the majority algorithm. (I hadn’t yet figured out the plurality algorithm.) Then I marked (1) those captures where experts and the algorithm disagreed, and (2) those captures that experts had said were particularly tricky. For these marked captures, I went through to catch any obvious blunders. For example, in one expert-classified capture, the expert classified the otherBirds in the images, but forgot to classify the giraffe the birds were on! The rest of these marked images I sent to Ali to look at. I didn’t tell her what the expert had marked or what the algorithm said. I just asked her to give me a new classification. If Ali’s classification matched with either the algorithm or the expert, I set hers as the official classification. If it didn’t, then she, and Craig, and I examined the capture further together — there were very few of these.

Huh? What giraffe? Where?
And that is how I came up with the expert data set. I went back this week to tally how the experts did on their first attempt versus the final expert data set. Out of the 4,428 classifications, 30 were marked as ‘impossible’ by Ali, 1 was the duiker (which the experts couldn’t get right by using the website), and 101 mistakes were made. That makes for a 97.7% rate of success for the experts. (If you look at last week’s graph, you can see that some of you qualify as experts too!)
Okay, and what did the experts get wrong? About 30% of the mistakes were what I call wildebeest-zebra errors. That is, there are wildebeest and zebra, but someone just marks the wildebeest. Or there are only zebra, and someone marks both wildebeest and zebra. Many of the wildebeest and zebra herd pictures are plain difficult to figure out, especially if animals are in the distance. Another 10% of the mistakes were otherBird errors — either someone marked an otherBird when there wasn’t really one there, or (more commonly) forgot to note an otherBird. About 10% of the time, experts listed an extra animal that wasn’t there. And another 10% of the time, they missed an animal that was there. Some of these were obvious blunders, like missing a giraffe or eland; other times it was more subtle, like a bird or rodent hidden in the grass.
The other 40% of the time were mis-identifications of the species. I didn’t find any obvious patterns to where the mistakes were; here are the species that were mis-identified:
| Species | Mistakes | Mistaken for |
| buffalo | 6 | wildebeest |
| wildebeest | 6 | buffalo, hartebeest, elephant, lionFemale |
| hartebeest | 5 | gazelleThomsons, impala, topi, lionFemale |
| impala | 5 | gazelleThomsons, gazelleGrants |
| gazelleGrants | 4 | impala, gazelleThomsons, hartebeest |
| reedbuck | 3 | dikDik, gazelleThomsons, impala |
| topi | 3 | hartebeest, wildebeest |
| gazelleThomsons | 2 | gazelleGrants |
| cheetah | 1 | hyenaSpotted |
| elephant | 1 | buffalo |
| hare | 1 | rodents |
| jackal | 1 | aardwolf |
| koriBustard | 1 | otherBird |
| otherBird | 1 | wildebeest |
| vervetMonkey | 1 | guineaFowl |
Better with experience
Does experience help with identifying Snapshot Serengeti images? I’ve started an analysis to find out.
I’m using the set of about 4,000 expert-classified images for this analysis. I’ve selected all the classifications that were done by logged-in volunteers on the images that had just one species in them. (It’s easier to work with images with just one species.) And I’ve thrown out all the images that experts said were “impossible.” That leaves me with 68,535 classifications for 4,084 images done by 5,096 different logged-in volunteers.
I’ve counted the number of total classifications each volunteer has done and given them a score based on those classifications. And then I’ve averaged the scores for each group of volunteers who did the same number of classifications. And here are the results:
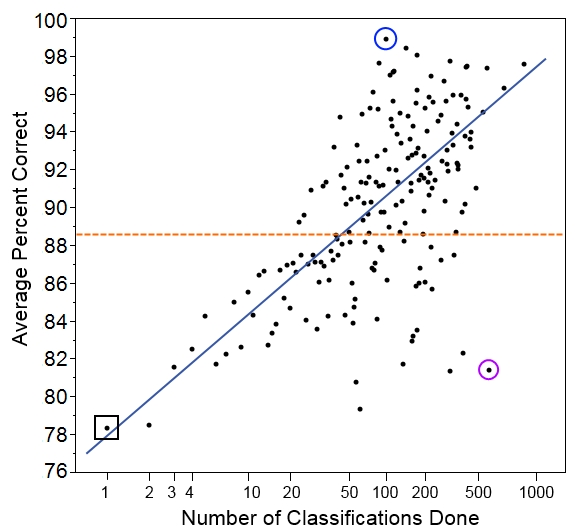
Here we have the number of classifications done on the bottom. Note that the scale is a log scale, which means that higher numbers get grouped closer together. We do this so we can more easily look at all the data on one graph. Also, we expect someone to improve more quickly with each additional classification at lower numbers of classifications.
On the left, we have the average score for each group of volunteers who did that many classifications. So, for example, the group of people who did just one classification in our set had an average score of 78.4% (black square on the graph). The group of people who did two classifications had an average score of 78.5%, and the group of people who did three classifications had an average score of 81.6%.
Overall, the five thousand volunteers got an average score of 88.6% correct (orange dotted line). Not bad, but it’s worth noting that it’s quite a bit lower than the 96.6% that we get if we pool individuals’ answers together with the plurality algorithm.
And we see that, indeed, volunteers who did more classifications tended to get a higher percentage of them correct (blue line). But there’s quite a lot of individual variation. You can see that despite doing 512 classifications in our set, one user had a score of only 81.4% (purple circle). This is a similar rate of success as you might expect for someone doing just 4 classifications! Similarly, it wasn’t the most prolific volunteer who scored the best; instead, the volunteer who did just 96 classifications got 95 correct, for a score of 99.0% (blue circle).
We have to be careful, though, because this set of images was drawn randomly from Season 4, and someone who has just one classification in our set could have already classified hundreds of images before this one. Counting the number of classifications done before the ones in this set will be my task for next time. Then I’ll be able to give a better sense of how the total number of classifications done on Snapshot Serengeti is related to how correct volunteers are. And that will give us a sense of whether people learn to identify animals better as they go along.
Science Shutdown
It’s Day 2 of the U.S. government shutdown. While the media blares about congressional politics and occasionally offers a run-down of what the shutdown may or may not mean for the average Joe, the impacts of the shutdown on science are not generally noted. Notice that I said ‘science’ and not ‘U.S. science’ because this shutdown affects scientists around the globe.
For starters, all the federal grant-making agencies are shut. This means no processing of grants, no review of proposals. Everything grinds to a halt. At best, it causes delays. But at worst, it means important science that depends on continuity gets interrupted, forcing some scientists to start their experiments over from scratch; for expensive experiments, it could mean a death knell. Other research that depends on getting funding before a field season may be delayed a year even if the government is shut down for only a few days.
Much of U.S. science is actually done by government employees. One agency, the United States Geological Survey, employs (oh, I can’t look up the number; the website is shut down; let’s just say “many thousands of”) scientists who work on topics like climate, ecosystems, earthquakes, and water quality. While some of these employees — like those who monitor for earthquakes, for example — will keep working as “essential” employees, most are furloughed. They get sent home with no pay and are forbidden by law to do any science. Forbidden. It’s a felony to work when furloughed. This hits home for me, as my husband is a post-doctoral geologist with the the U.S. Geological Survey and we are going without three-quarters of our household income for the length of the shutdown.
In addition to the direct impacts of the shutdown on government funding agencies and on government scientists, many more scientists are indirectly affected by issues of access. I am a fellow at the Smithsonian Institution’s National Museum of Natural History in Washington D.C., but I am employed by the University of Minnesota. The Smithsonian, being a quasi-governmental organization, is shut down. Most of the Smithsonian’s scientists are furloughed. (The folks in the entomology department, where I spend my time, are many of the ones that describe new species of insects previously unknown to science. No new species for a while, everyone. Sorry.) And on top of that, even people who aren’t employees of the Smithsonian (like me) cannot do their work, because they can’t get into the building. I know of visitors from other countries who came to visit the Museum for a few weeks to do research. But they can’t get in.
There are many, many scientists all over the world who collaborate with U.S. government scientists, who depend on U.S. government funding, and who use U.S. federal facilities. All these people are feeling the negative effects of the shutdown and aren’t able to get their science done.

A cheetah made from galaxies
This is what happens when astronomers haven’t gotten enough sleep. From Kyle Willett: a cheetah made out of many, many small galaxy images from Galaxy Zoo. Click it for the awesome full-sized image.

Human, 1, dancing
Seriously, this was too good not to share!

Handling difficult images
From last week’s post, we know that we can identify images that are particularly difficult using information about classification evenness and the fraction of “nothing here” votes cast. However, the algorithm (and really, all of you volunteers) get the right answer even on hard images most of the time. So we don’t necessary want to just throw out those difficult images. But can we?

Let’s think about two classes of species: (1) the common herbivores and (2) carnivores. We want to understand the relationship between the migratory and non-migratory herbivores. And Ali is researching carnivore coexistence. So these are important classes to get right.
First the herbivores. Here’s a table showing the most common herbivores and our algorithm’s results based on the expert-classified data of about 4,000 images. “Total” is the total number of images that our algorithm classified as that species, and “correct” is the number of those that our experts agreed with.
| species | migratory | total | correct | % correct |
| wildebeest | yes | 1548 | 1519 | 98.1% |
| zebra | yes | 685 | 684 | 100% |
| hartebeest | no | 252 | 244 | 96.8% |
| buffalo | no | 219 | 215 | 98.2% |
| gazelleThomsons | yes | 200 | 189 | 94.5% |
| impala | no | 171 | 168 | 98.3% |
We see that we do quite well on the common herbivores. Perhaps we’d wish for Thomsons gazelles to be a bit higher (Grants gazelles are most commonly mis-classified as Thomsons), but these results look pretty good.
If we wanted to be conservative about our estimates of species ranges, we could throw out some of the images with high Pielou scores. Let’s say we threw out the 10% most questionable wildebeest images. Here’s how we would score. (Note that I didn’t do the zebra, since they’d be at 100% again, no matter how many we dropped.) The columns are the same as the above table, except this time, I’ve listed the threshold Pielou score used to throw out 10% of the images of that species.
| species | Pielou cutoff | total | correct | % correct |
| wildebeest | 0.60 | 1401 | 1389 | 99.1% |
| hartebeest | 0.73 | 228 | 223 | 97.8% |
| buffalo | 0.76 | 198 | 198 | 100% |
| gazelleThomsons | 0.72 | 180 | 175 | 97.2% |
| impala | 0.86 | 155 | 153 | 98.7% |
We do quite a bit better with our Thomsons gazelle and increase the accuracy of all the other species at least a little. But do we sacrifice anything throwing out data like that? If wildebeest make up a third of our images and we have a million images, then we’re throwing away 33,000 images(!), but we still have another 300,000 left to do our analyses. One thing we will look at in the future is how much dropping the most questionable images affects estimates of species ranges. I’m guessing that for wildebeest it won’t be much.
What if we did the same thing for Thomsons gazelle or impala? We would expect about 50,000 images of each of those per million images. Throwing out 5,000 images still leaves us with 45,000, which seems like it might be enough for many analyses.
Now let’s look at the carnivore classifications from the expert-validated data set:
| species | total | correct | % correct |
| hyenaSpotted | 55 | 55 | 100% |
| lionFemale | 18 | 18 | 100% |
| cheetah | 6 | 6 | 100% |
| serval | 6 | 6 | 100% |
| leopard | 3 | 3 | 100% |
| jackal | 2 | 2 | 100% |
| lionMale | 1 | 1 | 100% |
| aardwolf | 1 | 1 | 100% |
| batEaredFox | 1 | 0 | 0% |
| hyenaStriped | 1 | 0 | 0% |
Wow! You guys sure know your carnivores. The two wrong answers were the supposed bat-eared fox that was really a jackal and the supposed striped hyena that was really an aardwolf. These two wrong answers had high Pielou scores: 0.77 and 0.83 respectively.
Judging by this data set, about 2.5% of all images are carnivores, which gives us about 25,000 carnivore images for every million we collect. That’s a lot of great data on these relatively rare animals! But it’s not so much that we want to throw any of it away. Fortunately, we won’t have to. We can use the Pielou score to have an expert look at the most difficult images.
Let’s say Ali wants to be very confident of her data. She can choose the 20% most difficult carnivore images — which is only about 5,000 per million images, and she can go through them herself. Five thousand images is nothing to sneeze at, of course, but the work can be done in a single day of intense effort.
In summary, we might be able to throw out some of the more difficult images (based on Pielou score) for the common herbivores without losing much coverage in our data. Further analyses are needed, though, to see if doing so is worthwhile and whether we lose anything by throwing out so many correct answers. For carnivores, the difficult images can be narrowed down sufficiently that an expert can double-check them by hand.
