
Detecting the right number of animals
This past spring, four seniors in the University of Minnesota’s Department of Fisheries, Wildlife, and Conservation Biology took a class called “Analysis of Populations,” taught by Professor Todd Arnold. Layne Warner, Samantha Helle, Rachel Leuthard, and Jessica Bass decided to use Snapshot Serengeti data for their major project in the course.
Their main question was to ask whether the Snapshot Serengeti images are giving us good information about the number of animals in each picture. If you’ve been reading the blog for a while, you know that I’ve been exploring whether it’s possible to correctly identify the species in each picture, but I haven’t yet looked at how well we do with the actual number of animals. So I’m really excited about their project and their results.
Since the semester is winding up, I thought we’d try something that some other Zooniverse projects have done: a video chat*. So here I am talking with Layne, Samantha, and Rachel (Jessica couldn’t make it) about their project. And Ali just got back to Minnesota from Serengeti, so she joined in, too.
Here are examples of the four types of covariates (i.e. potential problems) that the team looked at: Herd, Distance, Period, Vegetation
Herd: animals are hard to count because they are in groups

Herd
Distance: animals are hard to count because they are very close to or very far from the camera

Distance
Period: animals are hard to count because of the time of day

Period
Vegetation: animals are hard to count because of surrounding vegetation

Vegetation
* This was our first foray into video, so please excuse the wobbly camera and audio problems. We’ll try to do better next time…
We need an ‘I don’t know’ button!
Okay, okay. I hear you. I know it’s really frustrating when you get an image with a partial flank or a far away beast or maybe just an ear tip. I recognize that you can’t tell for sure what that animal is. But part of why people are better at this sort of identification process than computers is that you can figure out partial information; you can narrow down your guess. That partial flank has short brown hair with no stripes or bars. And it’s tall enough that you can rule out all the short critters. Well, now you’ve really narrowed it down quite a lot. Can you be sure it’s a wildebeest and not a buffalo? No. But by taking a good guess, you’ve provided us with real, solid information.
We show each image to multiple people. Based on how much the first several people agree, we may show the image to many more people. And when we take everyone’s identifications into account, we get the right answer. Let me show you some examples to make this clearer. Here’s an easy one:

And if we look at how this got classified, we’re not surprised:
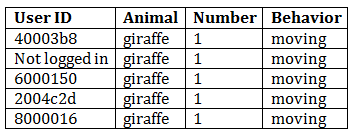
I don’t even have to look at the picture. If you hid it from me and only gave me the data, I would tell you that I am 100% certain that there is one moving giraffe in that image.
Okay, let’s take a harder image and its classifications:

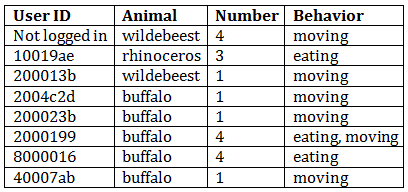
This image is, in fact, of buffalo – at least the one on the foreground is, and it’s reasonable to assume the others are, too. Our algorithm would also conclude from the data table that this image is almost certainly of buffalo – 63% of classifiers agreed on that, and the other three classifications are ones that are easily confused with buffalo. We can also figure out from the data you’ve provided us that the buffalo are likely eating and moving, and that there is one obvious buffalo and another 2 or 3 ones that are harder to tell.
My point in showing you this example is that even with fairly difficult images, you (as a group) get it right! If you (personally) mess up an image here or there, it’s no big deal. If you’re having trouble deciding between two animals, pick one – you’ll probably be right.
Now what if we had allowed people to have an ‘I don’t know’ button for this last image? I bet that half of them would have pressed, ‘I don’t know.’ We’d be left with just 4 identifications and would need to send out this hard image to even more people. Then half of those people would click ‘I don’t know’ and we’d have to send it out to more people. You see where I’m going with this? An ‘I don’t know’ button would guarantee that you would get many, many more annoying, frustrating, and difficult images because other people would have clicked ‘I don’t know.’ When we don’t have an ‘I don’t know’ button, you give us some information about the image, and that information allows us to figure out each image faster – even the difficult ones.
“Fine, fine,” you might be saying. “But seriously, some of those images are impossible. Don’t you want to know that?”
Well, yes, we do want to know that. But it turns out that when you guess an animal and press “identify” on an impossible image, you do tell us that. Or, rather, as a group, you do. Let’s look at one:

Now I freely admit that it is impossible to accurately identify this animal. What do you guys say? Well…

Right. So there is one animal moving. And the guesses as to what that animal is are all over the place. So we don’t know. But wait! We do know a little; all those guesses are of small animals, so we can conclude that there is one small animal moving. Is that useful to our research? Maybe. If we’re looking at hyena and leopard ranging patterns, for example, we know whatever animal got caught in this image is not one we have to worry about.
So, yes, I know you’d love to have an ‘I don’t know’ button. I, myself, have volunteered on other Zooniverse projects and have wished to be able to say that I really can’t tell what kind of galaxy that is or what type of cyclone I’m looking at. But in the end, not having that button there means that you get fewer of the annoying, difficult images, and also that we get the right answers, even for impossible images.
So go ahead. Make a guess on that tough one. We’ll thank you.
