
More accidental video
In processing Seasons 5 and 6, I recently stumbled upon a bunch of video files amongst the stills. You may recall that while we have our cameras set to take still images, every once in a while a camera gets accidentally switched to video mode. Then it takes 10-second (silent) clips. Most of these are “blanks” triggered by grass waving in the wind. But every once in a while, we get ten seconds of animal footage. Here are some from Season 5.
Zebras
Giraffe (peek-a-boo!)
Warthog
And, what do you think this is?
Summary of the Experts
Last week, william garner asked me in the comments to my post ‘Better with experience’ how well the experts did on the about 4,000 images that I’ve been using as the expert-identified data set. How do we know that those expert-identifications are correct?
Here’s how I put together that expert data set. I asked a set of experts to classify images on snapshotserengeti.org — just like you do — but I asked them to keep track of how many they had done and any that they found particularly difficult. When I had reports back that we had 4,000 done, I told them that they could stop. Since the experts were reporting back at different times, we actually ended up doing more than 4,000. In fact, we’d done 4,149 sets of images (captures), and we had 4,428 total classifications of those 4,149 captures. This is because some experts got the same capture.
Once I had those expert classifications, I compared them with the majority algorithm. (I hadn’t yet figured out the plurality algorithm.) Then I marked (1) those captures where experts and the algorithm disagreed, and (2) those captures that experts had said were particularly tricky. For these marked captures, I went through to catch any obvious blunders. For example, in one expert-classified capture, the expert classified the otherBirds in the images, but forgot to classify the giraffe the birds were on! The rest of these marked images I sent to Ali to look at. I didn’t tell her what the expert had marked or what the algorithm said. I just asked her to give me a new classification. If Ali’s classification matched with either the algorithm or the expert, I set hers as the official classification. If it didn’t, then she, and Craig, and I examined the capture further together — there were very few of these.

Huh? What giraffe? Where?
And that is how I came up with the expert data set. I went back this week to tally how the experts did on their first attempt versus the final expert data set. Out of the 4,428 classifications, 30 were marked as ‘impossible’ by Ali, 1 was the duiker (which the experts couldn’t get right by using the website), and 101 mistakes were made. That makes for a 97.7% rate of success for the experts. (If you look at last week’s graph, you can see that some of you qualify as experts too!)
Okay, and what did the experts get wrong? About 30% of the mistakes were what I call wildebeest-zebra errors. That is, there are wildebeest and zebra, but someone just marks the wildebeest. Or there are only zebra, and someone marks both wildebeest and zebra. Many of the wildebeest and zebra herd pictures are plain difficult to figure out, especially if animals are in the distance. Another 10% of the mistakes were otherBird errors — either someone marked an otherBird when there wasn’t really one there, or (more commonly) forgot to note an otherBird. About 10% of the time, experts listed an extra animal that wasn’t there. And another 10% of the time, they missed an animal that was there. Some of these were obvious blunders, like missing a giraffe or eland; other times it was more subtle, like a bird or rodent hidden in the grass.
The other 40% of the time were mis-identifications of the species. I didn’t find any obvious patterns to where the mistakes were; here are the species that were mis-identified:
| Species | Mistakes | Mistaken for |
| buffalo | 6 | wildebeest |
| wildebeest | 6 | buffalo, hartebeest, elephant, lionFemale |
| hartebeest | 5 | gazelleThomsons, impala, topi, lionFemale |
| impala | 5 | gazelleThomsons, gazelleGrants |
| gazelleGrants | 4 | impala, gazelleThomsons, hartebeest |
| reedbuck | 3 | dikDik, gazelleThomsons, impala |
| topi | 3 | hartebeest, wildebeest |
| gazelleThomsons | 2 | gazelleGrants |
| cheetah | 1 | hyenaSpotted |
| elephant | 1 | buffalo |
| hare | 1 | rodents |
| jackal | 1 | aardwolf |
| koriBustard | 1 | otherBird |
| otherBird | 1 | wildebeest |
| vervetMonkey | 1 | guineaFowl |
We need an ‘I don’t know’ button!
Okay, okay. I hear you. I know it’s really frustrating when you get an image with a partial flank or a far away beast or maybe just an ear tip. I recognize that you can’t tell for sure what that animal is. But part of why people are better at this sort of identification process than computers is that you can figure out partial information; you can narrow down your guess. That partial flank has short brown hair with no stripes or bars. And it’s tall enough that you can rule out all the short critters. Well, now you’ve really narrowed it down quite a lot. Can you be sure it’s a wildebeest and not a buffalo? No. But by taking a good guess, you’ve provided us with real, solid information.
We show each image to multiple people. Based on how much the first several people agree, we may show the image to many more people. And when we take everyone’s identifications into account, we get the right answer. Let me show you some examples to make this clearer. Here’s an easy one:

And if we look at how this got classified, we’re not surprised:
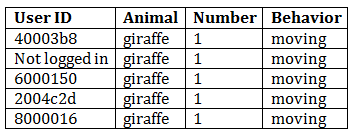
I don’t even have to look at the picture. If you hid it from me and only gave me the data, I would tell you that I am 100% certain that there is one moving giraffe in that image.
Okay, let’s take a harder image and its classifications:

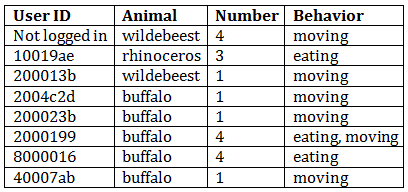
This image is, in fact, of buffalo – at least the one on the foreground is, and it’s reasonable to assume the others are, too. Our algorithm would also conclude from the data table that this image is almost certainly of buffalo – 63% of classifiers agreed on that, and the other three classifications are ones that are easily confused with buffalo. We can also figure out from the data you’ve provided us that the buffalo are likely eating and moving, and that there is one obvious buffalo and another 2 or 3 ones that are harder to tell.
My point in showing you this example is that even with fairly difficult images, you (as a group) get it right! If you (personally) mess up an image here or there, it’s no big deal. If you’re having trouble deciding between two animals, pick one – you’ll probably be right.
Now what if we had allowed people to have an ‘I don’t know’ button for this last image? I bet that half of them would have pressed, ‘I don’t know.’ We’d be left with just 4 identifications and would need to send out this hard image to even more people. Then half of those people would click ‘I don’t know’ and we’d have to send it out to more people. You see where I’m going with this? An ‘I don’t know’ button would guarantee that you would get many, many more annoying, frustrating, and difficult images because other people would have clicked ‘I don’t know.’ When we don’t have an ‘I don’t know’ button, you give us some information about the image, and that information allows us to figure out each image faster – even the difficult ones.
“Fine, fine,” you might be saying. “But seriously, some of those images are impossible. Don’t you want to know that?”
Well, yes, we do want to know that. But it turns out that when you guess an animal and press “identify” on an impossible image, you do tell us that. Or, rather, as a group, you do. Let’s look at one:

Now I freely admit that it is impossible to accurately identify this animal. What do you guys say? Well…

Right. So there is one animal moving. And the guesses as to what that animal is are all over the place. So we don’t know. But wait! We do know a little; all those guesses are of small animals, so we can conclude that there is one small animal moving. Is that useful to our research? Maybe. If we’re looking at hyena and leopard ranging patterns, for example, we know whatever animal got caught in this image is not one we have to worry about.
So, yes, I know you’d love to have an ‘I don’t know’ button. I, myself, have volunteered on other Zooniverse projects and have wished to be able to say that I really can’t tell what kind of galaxy that is or what type of cyclone I’m looking at. But in the end, not having that button there means that you get fewer of the annoying, difficult images, and also that we get the right answers, even for impossible images.
So go ahead. Make a guess on that tough one. We’ll thank you.
