
What we’ve seen so far…
As we prepare to launch Season 7 (yes! it’s coming soon! stay tuned!), I thought I’d share with you some things we’ve seen in seasons 1-6.
Snapshot Serengeti is over a year old now, but the camera survey itself has been going on since 2010; you guys have helped us process three years of pictures to date!
First, of the >1.2 million capture events you’ve looked through, about two-thirds were empty. That’s a lot of pictures of grass!

But about 330,000 photos are of the wildlife we’re trying to study. A *lot* of those photos are of wildebeest. From all the seasons so far, wildebeest made up just over 100,000 photos! That’s nearly a third of all non-empty images altogether.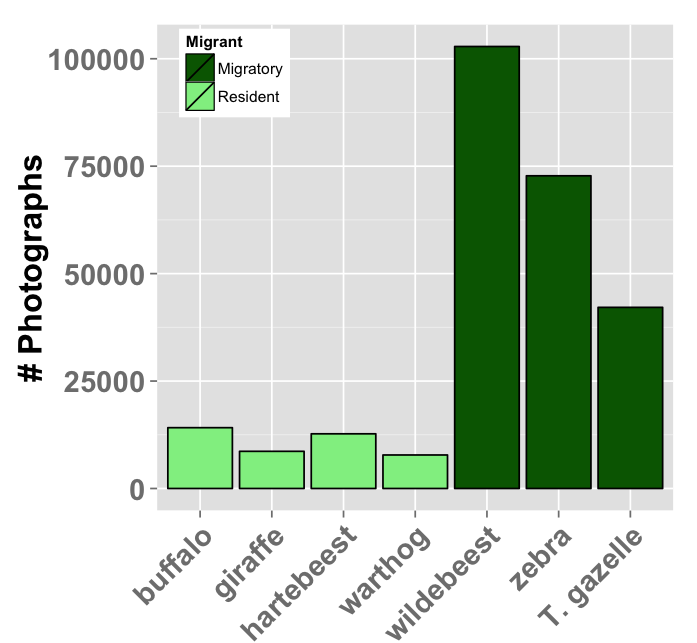
We also get a lot of zebra and gazelle – both of which hang out with the wildebeest as they migrate across the study area. We also see a lot of buffalo, hartebeest, and warthog — all of which lions love to eat.

We also get a surprising number of photos of the large carnivores. Nearly 5,000 hyena photos! And over 4,000 lion photos! (Granted, for lions, many of those photos are of them just lyin’ around.)
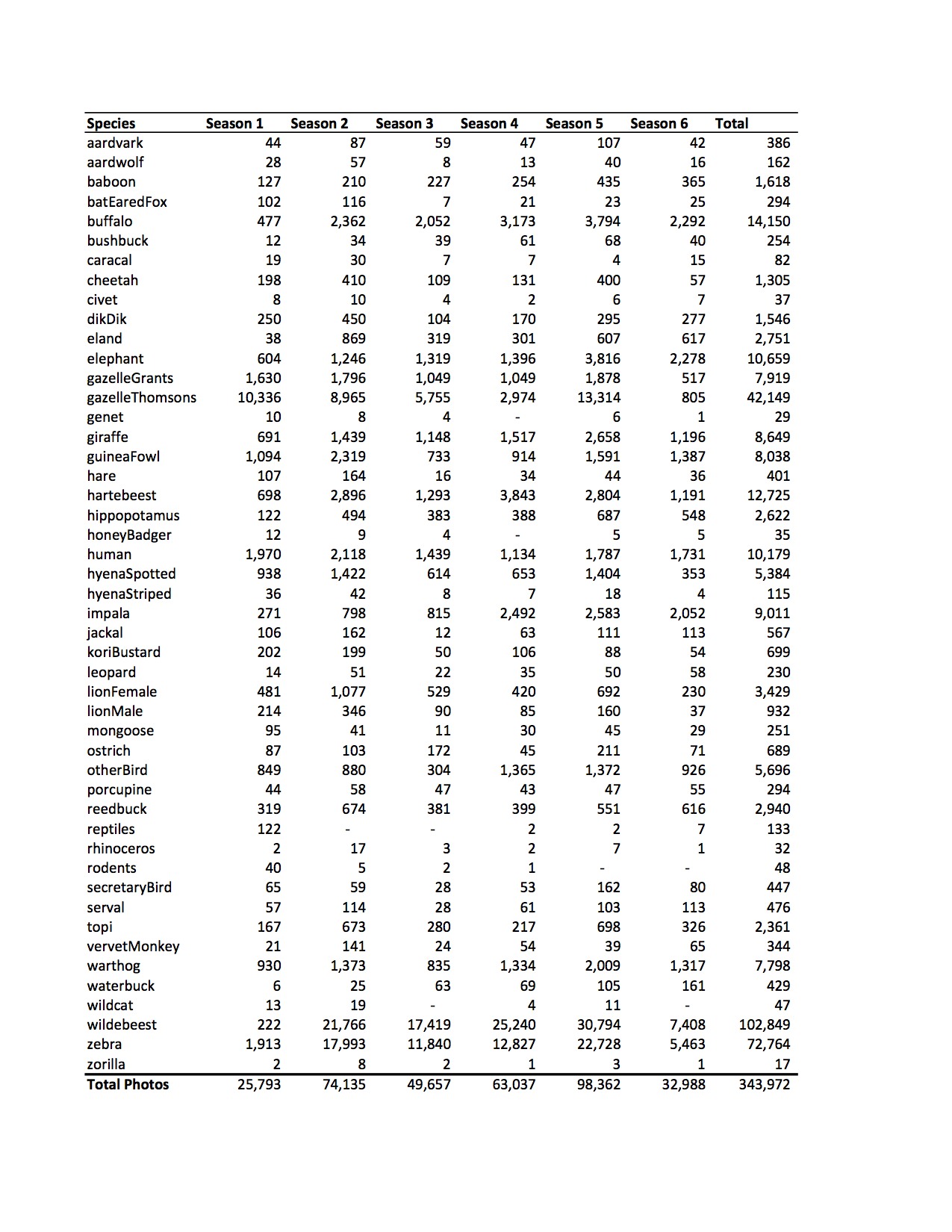
Curious what else? Check out the full breakdown below…
7 responses to “What we’ve seen so far…”
Trackbacks / Pingbacks
- - March 24, 2014

Fascinating breakdown of the photos. I’m not surprised at the 2/3 grass, though! How accurate are the ID’s? Were there really 17 photos of rhinos in season 2?
Good news about the imminent arrival of season 7 🙂
The IDs are actually really accurate: >96% correct! See Margaret’s blog post here: https://blog.snapshotserengeti.org/2013/06/07/majority-rules-algorithm/.
But there is some species-specific variation in accuracy, and we haven’t verified all the rhinos. But on the whole, you guys are really good!
Interesting is that I’ve seen more impalas than grant’s gazelles, according to their horns.
I have also noticed that appearance of some less common animals varies wildly per season (reptiles for an example). How much is this affected by:
1. In-site Vandalism?
2. Cameras being destroyed or rendered useless?
3. Different amount of pictures and cameras in different seasons?
4. People getting better at classifying the animals as the seasons progressed?
5. Real animal population change?
By the way, is the project currently running to get the animal data to be more accurate?
Hi Art –
There certainly is variation across seasons in which cameras are active. We try to keep the whole survey up and running all year round, but are constantly battling the elements and the wildlife who seem to love destroying the cams! Also, since the seasons sort of arbitrarily reflect when I am in Serengeti vs. Minnesota, they also vary in terms of total duration and months covered. So, I think that the variation across seasons in some of the rare animals has do to primarily with a chance, and secondarily with the different durations/active locations for the different seasons. The animals can also change their behavior across the seasons, though I don’t think that the difference in sightings of rare animals represents population change, because we just have too few sightings to accurately capture that.
And yep, one of our goals over the next year is to improve the (already awesome!) 96% accuracy rate of the plurality algorithm.
Cheers,
ali
Speaking of the plurality algorithm, I’ve had a few thoughts on it, and I’m curious what you think. In an earlier post, one of you mentioned an inherent tradeoff between “unclassifiable” incorrect IDs and true false positives. As I understand it, implementing the plurality algorithm increased the correct % by allowing for more classifications, but also boosted the number of false positives.
Could you get even more bang for your buck by trying different thresholds of agreement on a species ID (e.g. 30%, 35%, 40%) until you reach an optimal point? In other words, how does the total accuracy change as you progressively decrease the classification threshold below a majority?
Hi Tor —
Sorry for the slowwwww reply. That’s a really interesting idea. Although all the images get retired based on the same rule, we could tweak the reduction algorithm to report “final answers” based on species-specific agreement levels…. that’s something we’ll think about…thanks!