
Better with experience
Does experience help with identifying Snapshot Serengeti images? I’ve started an analysis to find out.
I’m using the set of about 4,000 expert-classified images for this analysis. I’ve selected all the classifications that were done by logged-in volunteers on the images that had just one species in them. (It’s easier to work with images with just one species.) And I’ve thrown out all the images that experts said were “impossible.” That leaves me with 68,535 classifications for 4,084 images done by 5,096 different logged-in volunteers.
I’ve counted the number of total classifications each volunteer has done and given them a score based on those classifications. And then I’ve averaged the scores for each group of volunteers who did the same number of classifications. And here are the results:
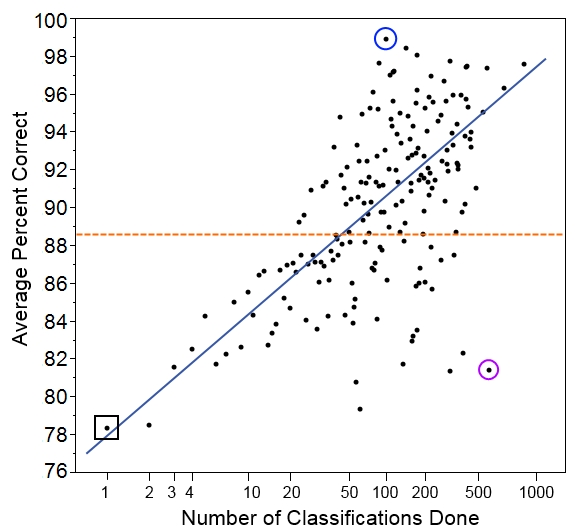
Here we have the number of classifications done on the bottom. Note that the scale is a log scale, which means that higher numbers get grouped closer together. We do this so we can more easily look at all the data on one graph. Also, we expect someone to improve more quickly with each additional classification at lower numbers of classifications.
On the left, we have the average score for each group of volunteers who did that many classifications. So, for example, the group of people who did just one classification in our set had an average score of 78.4% (black square on the graph). The group of people who did two classifications had an average score of 78.5%, and the group of people who did three classifications had an average score of 81.6%.
Overall, the five thousand volunteers got an average score of 88.6% correct (orange dotted line). Not bad, but it’s worth noting that it’s quite a bit lower than the 96.6% that we get if we pool individuals’ answers together with the plurality algorithm.
And we see that, indeed, volunteers who did more classifications tended to get a higher percentage of them correct (blue line). But there’s quite a lot of individual variation. You can see that despite doing 512 classifications in our set, one user had a score of only 81.4% (purple circle). This is a similar rate of success as you might expect for someone doing just 4 classifications! Similarly, it wasn’t the most prolific volunteer who scored the best; instead, the volunteer who did just 96 classifications got 95 correct, for a score of 99.0% (blue circle).
We have to be careful, though, because this set of images was drawn randomly from Season 4, and someone who has just one classification in our set could have already classified hundreds of images before this one. Counting the number of classifications done before the ones in this set will be my task for next time. Then I’ll be able to give a better sense of how the total number of classifications done on Snapshot Serengeti is related to how correct volunteers are. And that will give us a sense of whether people learn to identify animals better as they go along.
